
Healthcare Utilization Management Solutions
Improving treatment outcomes

UM sounds like a great idea in theory, however, in practice it encounters serious challenges. Assessing the appropriateness of care requires thorough evaluation of medical records of the patient and extracting relevant clinical facts from a mixture of free text notes, semi-structured and structured data. This process involves significant amounts of arduous manual labor. This is the most expensive and labor-intensive step in the process of UM.
Megaputer provides an automated solution for extracting clinical findings of interest from patient medical records. The solution relies on the use of advanced linguistic, semantic, and pattern recognition analysis performed by PolyAnalyst™ fine-tuned to the medical domain. It enables timely and accurate processing of all available data to extract and interpret clinical findings of interest.
The solution analyzes patient medical records extracted from standard EMR systems. It performs advanced linguistic analysis of textual records taking into account all intricacies of the medical domain (specialized negation expression, vocabulary, and notation conventions). The solution capitalizes on the use of multiple medical ontologies and semantic dictionaries, as well as on the use of elaborate XPDL™ queries for extracting vectors of features representing each of hundreds of important clinical parameters.
Once relevant clinical facts are extracted, they can be further analyzed to build models predicting the appropriateness of certain types of care with the help of machine learning algorithms trained on historical data. The solution can be implemented either at the customer site or at Megaputer’s secure data site.
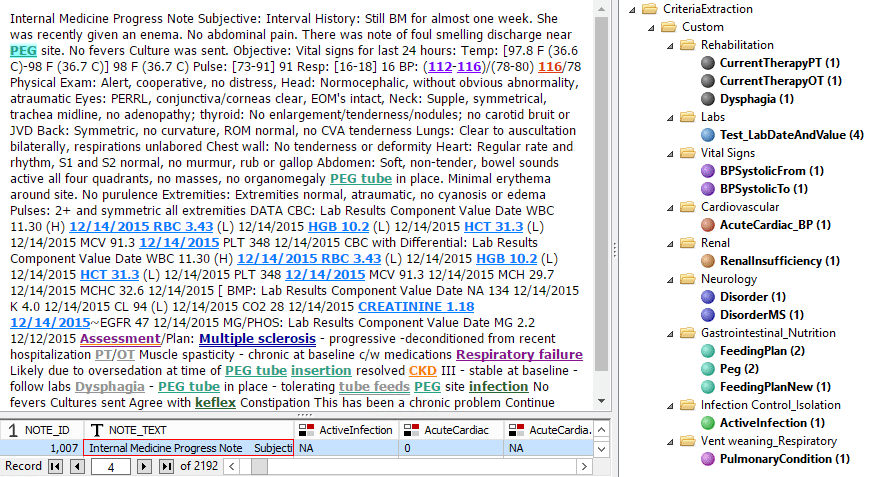
Electronic medical records hold a wealth of information including doctor and nurse notes and lab results that hospitals and physicians can use for improving patient care. However, a large portion of the data is stored as unstructured text. The complexity of textual data analysis, combined with the complexity of the medical domain per se, implied that only specially trained medical professionals were able perform manual analysis of this data, making the process of knowledge discovery in EMRs slow and expensive. See how the automated text analysis can improve that.



