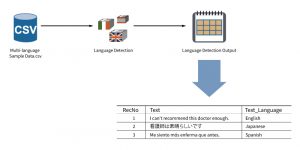
As our world becomes increasingly global, so does our data. Being an analyst working with almost any size company today often means facing the challenge of receiving text data that contains multiple languages. So what do you do?
As our world becomes increasingly global, so does our data. Being an analyst working with almost any size company today often means facing the challenge of receiving text data that contains multiple languages. So what do you do?
Essentially, there are two options we may consider: machine translation or native language analysis.
- With machine translation, we actually create a new dataset where the text has all been translated into a single language before we do the analysis. This makes the subsequent analysis much easier, as we only need to use a single language grammar module for the analysis.
- Native language analysis means that we keep documents in their original languages and perform a separate analysis for each language with the corresponding grammar module.