
 Machine Learning is hot right now. Really hot. And it’s come a long way from where it was over two decades ago. In 1996, IBM’s Deep Blue defeated world chess champion Garry Kasparov. This was a great achievement to mark the progress of the field, but chess is a relatively simple task and computers still struggled to be able to master more difficult tasks for another decade. Then, in the late aughts, machine learning started to boom like never before. In 2011, IMB’s Watson utilized live simultaneous natural language processing with information retrieval to defeat two Jeopardy! champions. In 2016, Google’s AlphaGo defeated Lee Sedol, who is claimed by many to be the strongest Go player in history. Despite the simplicity of Go’s rules, the game is extraordinarily complex. For perspective, there are more possible configurations of a Go board than there are atoms in the universe—and by this measure, Go is a googol more complicated than chess. To really appreciate the magnitude of this, consider that a googol (10100) is written as one followed by one hundred zeros, and the ratio of an electron (a sub-atomic particle) to the entire known universe is only 0.00000001% of a googol. It is a mind-boggling large number beyond human comprehension. And in a handful of years, machine learning has advanced by that scale.
Machine Learning is hot right now. Really hot. And it’s come a long way from where it was over two decades ago. In 1996, IBM’s Deep Blue defeated world chess champion Garry Kasparov. This was a great achievement to mark the progress of the field, but chess is a relatively simple task and computers still struggled to be able to master more difficult tasks for another decade. Then, in the late aughts, machine learning started to boom like never before. In 2011, IMB’s Watson utilized live simultaneous natural language processing with information retrieval to defeat two Jeopardy! champions. In 2016, Google’s AlphaGo defeated Lee Sedol, who is claimed by many to be the strongest Go player in history. Despite the simplicity of Go’s rules, the game is extraordinarily complex. For perspective, there are more possible configurations of a Go board than there are atoms in the universe—and by this measure, Go is a googol more complicated than chess. To really appreciate the magnitude of this, consider that a googol (10100) is written as one followed by one hundred zeros, and the ratio of an electron (a sub-atomic particle) to the entire known universe is only 0.00000001% of a googol. It is a mind-boggling large number beyond human comprehension. And in a handful of years, machine learning has advanced by that scale.
Recently, a program called AlphaStar learned virtually on its own how to play and master the wildly popular and challenging competitive real-time strategy video game StarCraft II. StarCraft II is so competitive that human players actually perform physical exercises with their fingers so that their reflexes are honed in order to strike the right keys as fast as possible. While Go merely involves placing pebbles on a grid, StarCraft II involves economic resource management, strategic combined arms combat, exploration, extensive future planning, processing streams of real-time information, and making rapid decisions.
Applications of Machine Learning
Machine Learning often gets flashy coverage when it reaches milestones in games, but it has slowly crept into our daily lives in ways we may not think about. When we post pictures on social media platforms like Facebook, our faces are instantly recognized and names are suggested of who to tag. When we watch movies or shows on platforms like Netflix, we get an endless stream of recommendations based on our past behavior. This same structure exists on the online shopping market such as Amazon. And it’s common for Apple’s Siri, Amazon’s Alexa, and Google’s Assistant to live in our homes and understand our requests.
Machine Learning is here to stay. And with Machine Learning technology sprinting into the future, everyone wants in. Companies are rapidly creating or bolstering existing analytics departments to utilize the craze. Unfortunately, like many hyped technologies, “Machine Learning” as a phrase can devolve into jargon, buzz words, oversimplifications, misnomers, and a lot of confusion. To many, Machine Learning is a mystery that seems indifferentiable from sorcery.
What is Machine Learning?
Machine Learning, like Artificial Intelligence, suffers from a name that tends to get bogged down in philosophy and pedantry. What does it mean to “learn?” What does it mean to hold “intelligence?” There is a good deal of discussion amongst computer scientists and others about this, but for our purpose it is just a rabbit hole. In fact, it is best to throw out our human conceptions of what “learn” and “intelligence” mean because they only add a biased expectation.
So, then, what is Machine Learning? In it’s simplest form, Machine Learning is essentially making a computer learn a complicated task by having the computer teach itself. We merely provide the computer some examples of how to do something, and the computer learns from those examples to help us fill in the holes and solve complex problems.
Now let’s break this process down. First, it is useful to identify our goals. Almost always, we would like to classify (assign discrete labels), perform regression (predict numerical values) on, or cluster (group similar things together) our data. For example, we could classify faces by if they are smiling or not. We could perform regression on weather data to predict tomorrow’s temperature. We could cluster stars together by grouping them based on how hot and bright they are.
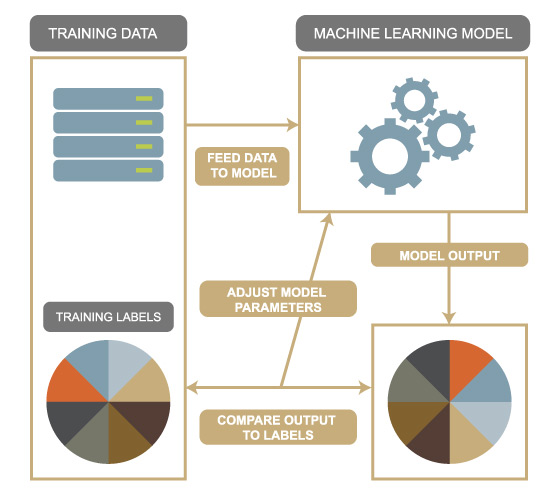
Now that we have a goal in mind, the question is by what method can we achieve this task? This is the “model.” Think of a model as a machine that you feed data into and which spits out classes, a regression, or clusters of that data. How do we build the model? Before Machine Learning, you would have to manually figure this out. This would involve having to draw specific blueprints for the machine, figure out the appropriate size of gears and their exact positions, assemble the machine, and test it.
In this analogy, Machine Learning is like building a special type of machine. This machine has gears that can change size and position. Also, if you provide the machine with the desired output, it can run data through itself and check the resulting output with this desired output. If they don’t match, the machine knows how to change the size and position of the gears to make it more likely to be correct in the future. And it can repeat this over and over again until it is has found the best arrangement of gears. This is essentially Machine Learning, and all it took was having a special device and labeled data it could look at. No human was needed to tell it where to place the gears.
This is just an analogy, but it works very similarly in our digital space. We construct a digital model that is parameterized by certain variables. We feed training data labeled by the desired output into the model and see the actual output. We then compare the actual output to the labels, which is our desired output. We note the error and use math to compute in what direction and by how much we should tweak the parameters of the model. And repeat. The machine doesn’t make decisions or figure out concepts on its own. It is programmed to use Calculus, Information Theory, Probability, and Statistics to calculate numbers to fudge the parameters by.
 In the end, Machine Learning is not what most humans consider “learning.” It is driven by math, algorithms, and data. For those who aren’t fascinated by the math and theory of Machine Learning, this can destroy the mystique somewhat. Personally, although the Man Behind the Curtain is not what we might expect or desire, he is intriguing all the same. In fact, as computer scientists and cognitive scientists study Machine Learning more we start to suspect that there isn’t as much of a disconnect as we might suspect. We may think that Machine Learning is so unlike humanity, but it may be the case that humanity is more like Machine Learning than we suspect. Our own brains may be just like a cold math-algorithm-data amalgam, but on a massive and complex scales.
In the end, Machine Learning is not what most humans consider “learning.” It is driven by math, algorithms, and data. For those who aren’t fascinated by the math and theory of Machine Learning, this can destroy the mystique somewhat. Personally, although the Man Behind the Curtain is not what we might expect or desire, he is intriguing all the same. In fact, as computer scientists and cognitive scientists study Machine Learning more we start to suspect that there isn’t as much of a disconnect as we might suspect. We may think that Machine Learning is so unlike humanity, but it may be the case that humanity is more like Machine Learning than we suspect. Our own brains may be just like a cold math-algorithm-data amalgam, but on a massive and complex scales.
The Importance of Data
Data is a pillar of Machine Learning. Without data we cannot build anything. The math doesn’t change, and while we can build clever model structures to help with the learning process, without good data our models will fail. We luckily live in an age of data. Large amounts of data allow models to be extremely fine-tuned. It allows for advanced model structures like Deep Neural Networks. Publicly available data sets such as MNIST and ImageNet for image processing have allowed data scientists to easily compare models and share knowledge. Data is revolutionizing entire fields and Machine Learning is no exception.
But with great power comes great responsibility. If our data is not labeled well or if it is biased from how it is collected, that error or bias is directly injected into the model. After all, the model is simply trying to mimic the data used to create it. Bad data in, bad model out.
Biased data can lead to very poor model performance. For example, last year MIT Media Lab showed that facial recognition from Microsoft, IBM, and Face++ weren’t very good at identifying women or person’s with darker skin, most likely because they didn’t have enough examples of those types of faces in their training data.
So big data is great for our ability to model the world. But the purity and completeness of the data we use in Machine Learning should always be considered when building a model.
The Future
Well, Machine Learning is the future. Tasks that we do effortlessly as humans, such as processing sound and sight, are extraordinarily complicated. Without Machine Learning it would take monumental effort to create machines to do them effectively, and for the tasks that even we as humans find hard, machines would be hopeless. We live in the age of data and increasingly cheap computational power. Machine Learning is thriving and adapting. If you are interested in Machine Learning, check out this video for more insights.
And stay tuned for future blog posts on Machine Learning as we examine different applications and different models used.
READ MORE: Convolutional Neural Networks