

Data cleansing is critical in data analysis. The quality of data cleansing has a direct impact on the accuracy of the derived models and conclusions. In practice, data cleaning typically accounts for between 50% and 80% of the analysis process.
Traditional data cleansing methods are mainly used to process structured data, including the completion of missing data, modification of format and content errors, and removal of unwanted data. Resources on these methods are widely available. For example, big data engineer Kin Lim Lee published an article on this topic. Lee’s article introduced eight commonly used Python codes for data cleaning. These codes for data cleaning were written by functions and can be used directly without changing parameters. For each piece of code, Lee gave the purpose and also gives comments in the code. You can bookmark this article and use it as a toolbox.
However, the amount of unstructured (textual) data in the world has grown exponentially in recent years. Today, more than 80% of data is unstructured. It has now become important to have high-precision text data cleansing capabilities built into your analysis platform. In fact, this should be a fundamental requirement when assessing text analysis software.
In this article we will discuss the three main steps of text data cleansing (spell check, abbreviation expansion, and identification of abnormalities). Meanwhile, we will gradually introduce a few advanced natural language processing techniques that improve the precision of the data cleansing process.
 Spell Check:
Spell Check:
The spell check process includes finding slang terms, splitting merged words, and correcting spelling errors. Social media is full of slang words. These words should be converted to standard ones when working with free text. Words like “luv” or “looooveee” will be converted to “love”, and “Helo” will be converted to “Hello”. The text is sometimes accompanied by words that are merged together, such as RainyDay and PlayingInTheCold. Spelling errors can also occur by a simple transposition error, such as “sepll cehck”. One difficulty in spell checking is to find semantic errors, where the word is spelled correctly but it does not fit the context. For example, “there are some parts of the word where even now people cannot write”. In this case, “world” was mistakenly spelled as “word”. Without context, this type of error is hard to find.
In terms of automatic spell checking, PolyAnalyst™ has reached a very high level of accuracy. Different spelling errors will be identified along with automatically chosen spelling corrections. The output will be a model that consists of a mapping between incorrect terms and chosen corrections. You can view the results to check the corrections that will be applied. You can also modify the properties of the software to make changes to the list of suggested corrections. We’ll see a detailed example of this in the next section.
 Abbreviation Expansion:
Abbreviation Expansion:
Another important part of text data cleansing is abbreviation expansion. There are many forms of abbreviations. Common forms often omit the last/intermediate letters or word, or extract the first letter of each word in a phrase. For example, “Rd” for “road”, ” tele” for “television”, and “ASAP” for “as soon as possible”. Some abbreviations are just based on people’s daily usage habits, like “Tsp” for “teaspoons”. Some abbreviations are borrowed from another language, like “LB” being the Latin abbreviation of “libra pondo”, which we commonly use in English to abbreviate “pound”. One problem with abbreviation expansion is that the same abbreviation may have different expansions, depending on the topics been discussed. For example, “ASA” can represent “American Society of Anesthesiologists” , “Acoustical Society of America”, “American Standards Association” or “acetylsalicylic acid” (a.k.a., Aspirin).
In terms of complicated abbreviation expansion, PolyAnalyst™ can extract any abbreviations deciphered in the text. If an abbreviation is not deciphered in the text, a machine learning approach will be used to learn patterns of abbreviation/acronym formation on the basis of the local context. For example, when dealing with English medical abbreviations, the customized abbreviation expansion model can be trained on the basis of the English language database PubMed. And the algorithm can be trained to work with abbreviations from any other thematic area.
 Identify Abnormalities:
Identify Abnormalities:
Abnormal values may be caused by system errors or by human input errors. A common method of detecting abnormal values is to set a normal range to locate suspicious records that are not within the defined range. For example, if records show some employees are younger than 18 years old, or if their annual income is over 5 million dollars, we can label them as suspicious records. In transactional data, if we found some transactions were made before customer account data was created, then we can label them as abnormal.
When we deal with unstructured data, the normal range is not always obvious. Here is one common example. In a set of employee survey data, free text comments show that some employees give extremely positive reviews towards their company. Meanwhile, they give zero (very dissatisfied) in the numerical rating of the company. A common cause of this situation is from a system default setting. If the employee did not provide a rating, some systems automatically pad the empty score with zero. A score of zero is within the normal range, which prevents us from detecting these exception records. It is impossible for us to manually read thousands of records for verification. Instead, we can apply sentiment analysis to textual reviews to help detect these types of abnormalities. Sentiment analysis is the process of computationally identifying opinions in the texts as positive, negative, or neutral (read more about this topic here). By comparing the sentiment analysis results with the overall scores, we can find discrepancies, and thus potential abnormal records, due to system errors.
Examples of data cleansing in PolyAnalyst:
PolyAnalyst provides an out-of-box data cleansing solution to handle massive amounts of text data. The spell check function uses a well-designed dictionary system to check the spelling of the words, and gives corresponding suggestions according to the context. Let’s take a look at one real world example here:
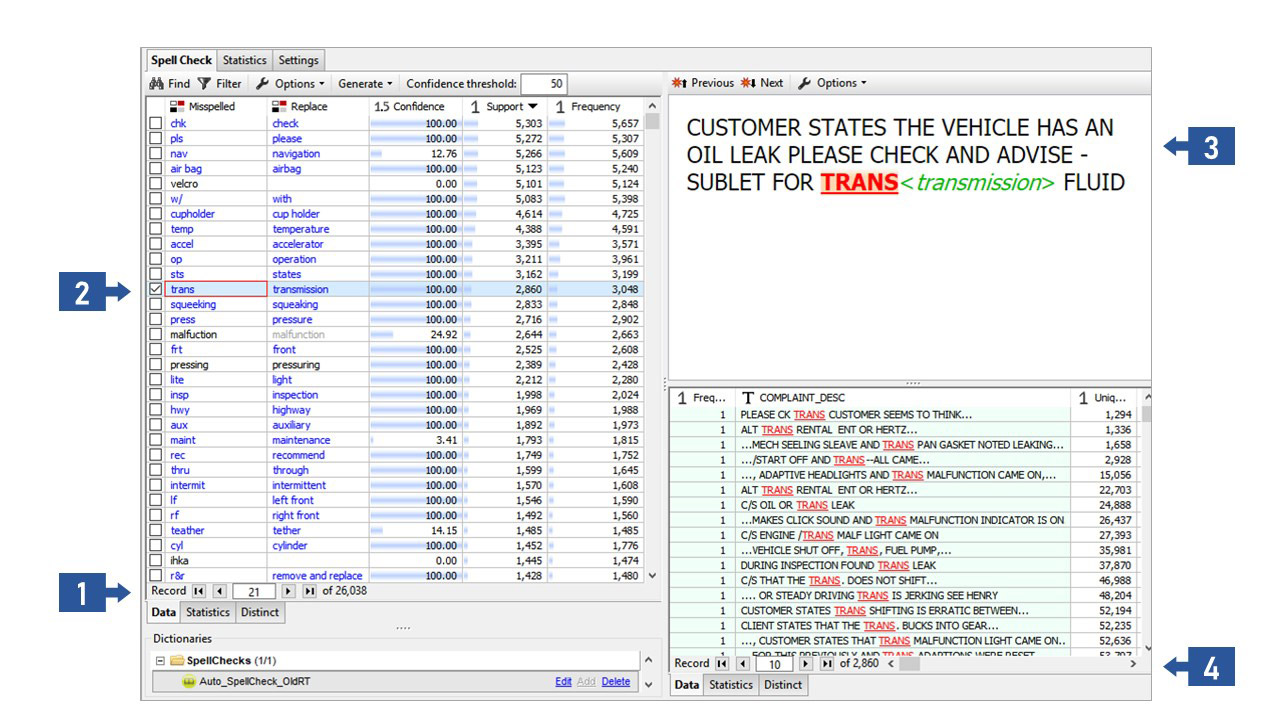
This is the result of spell check analysis on car repair records. The total amount of data is 13 million records and the execution time is 87 minutes. The results show that a total of 26,038 different spelling errors have been detected, as indicated by section 1 of the figure. The upper left part of the panel can be used to view each misspelled form, the confidence level, the correct word to be replaced, and the number of individual errors. For example, “trans” is suggested to be replaced by “transmission” (section 2 of the figure). We see that the confidence level is 100%, there are 2860 records with similar spelling errors, and the total number of times this error occurs in the dataset is 3048. We can also check the detailed information in the right half of the panel. As shown in section 3 of the figure, “Customer states the vehicle has an oil leak please check and advice- sublet for trans fluid”. Normally “trans” can be used to express many different meanings, such as “translate”, “transform”, or “transgender”. But according to the context here, “trans” should be replaced by “transmission”. And we can see that there are 2860 records with the same error, as indicated in section 4 of the figure. In this way, PolyAnalyst™ offers users unique advantages when cleaning and processing large-scale data. In addition to having high processing speed, the built-in data cleansing features also take into account multiple types of text errors and anomalies while providing highly accurate modification methods for text that correspond to the current text environment.
Conclusion:
Data cleaning is indeed a key part of data analysis. The addition of text content has increased the difficulty of data mining. But the gain is obvious. It brings much more information. Proper handling of the text data will help us to reach more enriched conclusions from data analysis. Through this article, we hope that everyone gains a general understanding of text data cleansing. If you are interested in learning more about PolyAnalyst™, or viewing a free, personalized demonstration of the data cleansing or sentiment analysis process, please don’t hesitate to contact us.